TF = TN לכן אין הרבה למה לצפות:
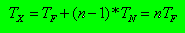
TX שווה לזמן הבאת רשומה + זמן הבאת הרשומה הלוגית הבאה כפול מספר
הרשומות בקובץ. מכיוון שהסדר הלוגי שווה לסדר הפיסי קיבלנו מדד יקר
לקריאה ממצה של הערימה.
TY מדד לארגון מחדש של הקובץ.
אם היו הרבה ביטולים לוגיים בערימה נרצה לארגן את הקובץ מחדש.
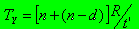
TY שווה לקריאת n רשומות + כתיבת n-d רשומות חיות (לא מבוטלות) כפול קצב
העברת נתונים רבים. ההנחה היא שקודם קוראים את הערימה הישנה
ואח"כ כותבים את הערימה החדשה, אבל אם הערמות (הישנה והחדשה)
נמצאות בדיסקים שונים או אפילו באותו דיסק או באותו שטח, בכל מקרה,
הקריאה של הערמה הישנה והכתיבה של הערמה החדשה נעשות במקביל
(כי הפרעות נלקחות בחשבון על ידי t’ ) ואז העלות היא:
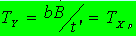
TY שווה לזמן קריאה ממצה השווה לזמן כתיבה ממצה (2 הפעולות שנעשות במקביל) וזה שווה לזמן קריאה ממצה פיזית (לפי הסדר הפיסי של הרשומות). קיבלנו חצי מהעלות TY שהנחנו קודם.
לסיכום, בערימה קיבלנו שהמדדים מאופייני קריאה גרועים ביותר בעוד שהמדדים מאופייני כתיבה הם טובים, לכן קובץ ערמה הוא בבירור קובץ מאופיין כתיבה.
אבל מה אם צריכים מבנה קובץ שדווקא מאופיין קריאה?