TF זמן הבאת רשומה כלשהי.
מגישים שאילתה לקובץ ומצפים לתשובה אחת - הרשומה הראשונה שעונה על הדרישה, אבל בערימה אולי דווקא רוצים את הרשומה האחרונה (הדיווח האחרון שנכתב בקובץ)?
בהנחה של הסתברות אחידה לכל רשומה להיות התשובה, המספר הממוצע של גושים נקראים עד לאיתור התשובה הוא חצי קובץ:
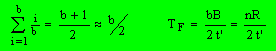
הסבר: הקובץ מורכב מ- b גושים ומ- n רשומות. כאשר מניחים הסתברות אחידה יש סיכוי של b /1 לכל גוש להיקרא. מספר ממוצע של גושים נקראים הוא b / 2 . לכן זמן הבאת רשומה כלשהי מהקובץ הוא:
קצב העברת הנתונים / (גודל גוש X מספר ממוצע של גושים נקראים) = TF
בערימה אין סדר ואין מושג היכן הרשומה שמחפשים נמצאת, לכן עלות הבאת רשומה היא גבוהה. לצורך ייעול נשתמש בחיפוש אצווה.
חיפוש אצווה (Batch Fetch) - צוברים מספר שאילתות (m) ומפעילים אותן יחד בפעם אחת על כל הערימה. נחשב את (m) TF כאשרm הוא מספר התשובות המבוקש.
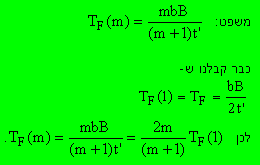
בשביל m גדול 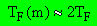 שזה פשוט קריאת (כמעט) כל הקובץ.
שזה פשוט קריאת (כמעט) כל הקובץ.
עבור m>2 משתלם לעשות חיפוש אצווה, אבל החיסרון הוא שלוקח זמן עד מצטברות m שאילתות.